The success of Internet and rapid improvements in processing and storage technologies have made computing resources more ubiquitously available, more efficient, and more available than ever before. This has enabled provisioning of computing resources (e.g., CPU and storage) to be leased and released as general utilities over the Internet in an on-demand fashion. The services in cloud computing are provided by infrastructure providers and service providers. The infrastructure providers manage cloud platforms and provide resources according to usage based pricing model. The service providers rent resources from one or many infrastructure providers to serve the end users. The infrastructures providers are generally large companies such as Google, Amazon and Microsoft which can handle huge expenses associated with managing a cloud platform.
The service providers seek to reshape their business models in order to gain benefit from the platform provided by infrastructure providers. Indeed, cloud computing has several advantages which makes it attractive to business owners such as no up-front investment, lower operation cost, highly scalable, easy access, reduced business risks, maintenance expenses. However, although cloud computing offers several advantages, it also brings many unique challenges that need to be carefully addressed. One such challenge in cloud computing is the enormous amount of energy consumed in data centers.
Improving energy efficiency of data centers is a major challenge in cloud computing.It has been estimated that cost of powering and cooling accounts for 53% of the total operational expenditure of data centers. In 2012, the data centers worldwide consumed 300-400 tera-watt hours of electrical energy, which is about 2% of the global electricity usage, and it is to consume 1/5th of earth’s power by 2025[1]. Hence, the infrastructure providers are under pressure to reduce energy consumption.
Virtual Machine(VM) consolidation using live VM migration optimizes power utilization by running VMs in as much few servers as possible and putting the rest in sleep mode or turning them off. Several good VM placement algorithms have been proposed and are used in OpenStack Neat[2] and CloudSim[3], but these algorithms do not consider the heterogeneity of servers in data centers.
The basic idea behind efficient VM placement algorithms is that VMs from an underloaded server are migrated to a different server, so that a server all of whose VMs are migrated can be put in sleep mode or turned off. According to the study in [6], a typical HP blade server consumes 450 w at peak load, 270 w at idle state and 10.4 w at sleep mode
CloudSim simulator uses Power Aware Best-Fit Decreasing (PABFD). The PABFD places the VM on the host where estimated increase in power consumption is minimum.
The problem with this algorithms is that they tend to overload the same servers, and do not consider the heterogeneity in servers while deciding a server to place VM. Moges and Abebe [7] have proposed some VM placement algorithms which consider the heterogeneity in servers and also outperform the two algorithms mentioned above.
where,
OVERLOADthr : is overload threshold of resource utilization level,
UNDERLOADthr : is underload threshold of resource utilization level.
Then MF rule is defined to favor a host whose resource level has a minimum distance from Ld. More precisely,
Allocated − host = min|Lh − Ld| ,
where,
Lh : is the current load on the host.
The MF rule with items sorted by decreasing is called a Medium-Fit Decreasing (MFD).The MFD algorithm minimizes the overload probability and at the same time minimizes the number of active servers. To understand the reason behind this consider the following scenario:
Suppose all hosts have their utilization below the desired level. Then VMs will be migrated from lowest loaded hosts to the host which has its utilization level nearest to the desired level, in this case, the highest loaded server. This process is repeated until a considerable number of servers have their utilization near to the desired level. The hosts whose VMs are migrated are put in sleep mode or powered off. Thus, the number of servers are minimized and at the same time the highest loaded servers do not pass their overload thershold.
Similarly, if some of the servers are overloaded then their VMs will be migrated to servers whose utilization is nearer to the desired level. Thus, in both cases overload probability is minimized, which in fact reduces SLA violations and VM migrations.
PE = CPUtotal/POWERmax ,
where,
CPUtotal is the total processing capacity of host
POWERmax is the power of a host at 100% load
Thus, an efficient VM placement algorithm can:
1) Minimize the number of active servers by using bin-packing heuristics such as FFD and BFD.
2) Favor the host higher PE.
3) Combine the above two rules.
We will discuss algorithms that follow the third rule.
Even in heterogeneous scenario all proposed algorithms outperform baseline algorithms. All proposed algorithms give median energy consumption of about 35.3 kwh using PlanetLab workload traces. MBFD has highest energy consumption with a median value of 107.6kwh while that of PABFD is 48.5kwh.
The improvement of proposed algorithms over baseline is about 67%, and 60% in case of Bitbrains traces. The improvement of MFPED over MBFD is 68% for OTF and 46% for VM migrations in PlanetLab traces. For Bitbrains traces MFPED shows 78% less OTF and 40% less VM migrations.
Thus the improvement in this case is even more significant than the improvement in default scenario.
Performance in homogeneous scenario
There is no energy saving by proposed algorithms over baseline algorithms in terms of energy consumption. However, there is improvement in terms of OTF and VM migrations shown by MFPED. Since, all hosts same power efficiency, the only power saving option is to minimize he number of hosts. The worst energy consumption is by PABFD in both traces. MFPED has 19% less OTF and 9% less VM migrations as compared to MBFD in PlanetLab traces, while in Bitbrains traces there is 42% and 14%, lesser OTF and VM migrations respectively.[9]
Time Complexity of algorithms
Thermal aware VM consolidation can be done taking into account server temperature. Cooling systems are also major contributors in the operational cost of data centers. The cost required for cooling the data centers can be reduced by preventing the servers from excessive heating.
The service providers seek to reshape their business models in order to gain benefit from the platform provided by infrastructure providers. Indeed, cloud computing has several advantages which makes it attractive to business owners such as no up-front investment, lower operation cost, highly scalable, easy access, reduced business risks, maintenance expenses. However, although cloud computing offers several advantages, it also brings many unique challenges that need to be carefully addressed. One such challenge in cloud computing is the enormous amount of energy consumed in data centers.
 |
| Source:[1] |
Improving energy efficiency of data centers is a major challenge in cloud computing.It has been estimated that cost of powering and cooling accounts for 53% of the total operational expenditure of data centers. In 2012, the data centers worldwide consumed 300-400 tera-watt hours of electrical energy, which is about 2% of the global electricity usage, and it is to consume 1/5th of earth’s power by 2025[1]. Hence, the infrastructure providers are under pressure to reduce energy consumption.
Virtual Machine(VM) consolidation using live VM migration optimizes power utilization by running VMs in as much few servers as possible and putting the rest in sleep mode or turning them off. Several good VM placement algorithms have been proposed and are used in OpenStack Neat[2] and CloudSim[3], but these algorithms do not consider the heterogeneity of servers in data centers.
Virtualization
 |
| Source:[4] |
VMs are created by running the virtualization software on servers. The
fundamental idea behind a VM is to abstract the hardware of a single
computer (CPU, memory, disk drives, network interface cards, and so
forth) into several different execution environments, thereby creating
the illusion that each separate execution environment is running its own
private computer[4].
In cloud computing, virtualization is used to abstract the details of physical hardware and provide virtualized resources to high-level applications. Virtualization forms the foundation of cloud computing, as it provides the capability of pooling computing resources from clusters of servers and dynamically assigning or reassigning virtual resources to applications on-demand[5].
Problem Description
Live migration of VMs allows transferring a VM between physical nodes. An efficient VM placement algorithm is expected to allocate computing resources in such a way that it satisfies VM’s resource demand and minimizes energy utilization with the least number of VM migrations possible. The resource demand is usually specified as Service Level Agreement (SLA). SLA is an agree-
ment between cloud service provider and the customer. The expected Quality of Service (QoS) is specified in SLA. Energy efficiency has a trade-off with QoS, thus, increasing energy efficiency by maximizing CPU utilization may result in SLA violation.
ment between cloud service provider and the customer. The expected Quality of Service (QoS) is specified in SLA. Energy efficiency has a trade-off with QoS, thus, increasing energy efficiency by maximizing CPU utilization may result in SLA violation.
Cloud service provider needs to pay penalties for each SLA violation. Thus, any good consolidation algorithm must provide a well-balanced energy efficiency and SLA assurance. In addition to these two aspects, there is a third aspect of consolidation algorithms that deals with minimizing the number of VM migrations. VM migrations increase network traffic and also have energy cost associated with them. Thus, an energy aware VM placement algorithm must
take care of the following three aspects of consolidation:
take care of the following three aspects of consolidation:
1 Minimize energy utilization.
2 Minimize SLA violation.
3 Minimize VM migrations.
2 Minimize SLA violation.
3 Minimize VM migrations.
The basic idea behind efficient VM placement algorithms is that VMs from an underloaded server are migrated to a different server, so that a server all of whose VMs are migrated can be put in sleep mode or turned off. According to the study in [6], a typical HP blade server consumes 450 w at peak load, 270 w at idle state and 10.4 w at sleep mode
Existing VM placement algorithms
To address the consolidation issues a number of VM placement algorithms have been proposed. Not all of these algorithms deal with all the three aspects of consolidation. The objective function is a linear combination of cost of performance degradation, VM migration, and cost of energy. The resulting mathematical programming is a Mixed-Integer Nonlinear Program(MINLP) which is known to be NP-hard.
The problem of VM placement fits in the category of bin packing problem. In the bin packing problem items of different volumes need to be placed into bins of same volumes. In this case, items are analogous to VMs and bins are analogous to servers or hosts.
The problem of bin packing is an NP-hard problem, thus to find optimal solution we need to apply brute force approach which is not suitable for cloud environment. Thus, heuristic algorithms can be used to obtain feasible solution. The following heuristics for bin packing problems are useful for VM placement :
First-Fit(FF) : Assigns an item to the first partially filled bin that fits it. Otherwise, a new bin is opened.
Best-Fit(BF) : Assigns an item to the fullest partially filled bin that fits it. Otherwise, a new bin is opened.
OpenStack Neat is a software framework and open-source implementation for VM consolidation on OpenStack cloud. OpenStack is an open source cloud management tool for private and public cloud. OpenStack is an Iaas (Infrastructure as a Service) provider.
If you are new to OpenStack, please refer to this video:
OpenStack Neat applies consolidation process by invoking public APIs of OpenStack. The OpenStack Neat contains four decision components for VM consolidation:
1 Host overload detection: detect whether a host is overloaded.
2 Host underload detection: detect whether a host is underload.
3 VM selection: select the VMs to be migrated.
4 VM placement: select the host where the VMs should be migrated.
2 Host underload detection: detect whether a host is underload.
3 VM selection: select the VMs to be migrated.
4 VM placement: select the host where the VMs should be migrated.
The VM placement algorithm of OpenStack Neat is, Modified Best-Fit Decreasing (MBFD). The MBFD selects host with minimum available CPU that fits the VM, in case of a tie the host with smallest available RAM is chosen.

|

Newly proposed VM placement algorithms
Moges and Abebe [7] have proposed a new heuristic for bin packing problem called medium-fit. The medium fit heuristic is defined as follows:
Let Ld be the desired resource utilization level of a host given by,
Ld = (OVERLOADthr + UNDERLOADthr) /2 ,
where,
OVERLOADthr : is overload threshold of resource utilization level,
UNDERLOADthr : is underload threshold of resource utilization level.
Then MF rule is defined to favor a host whose resource level has a minimum distance from Ld. More precisely,
Allocated − host = min|Lh − Ld| ,
where,
Lh : is the current load on the host.
The MF rule with items sorted by decreasing is called a Medium-Fit Decreasing (MFD).The MFD algorithm minimizes the overload probability and at the same time minimizes the number of active servers. To understand the reason behind this consider the following scenario:
Suppose all hosts have their utilization below the desired level. Then VMs will be migrated from lowest loaded hosts to the host which has its utilization level nearest to the desired level, in this case, the highest loaded server. This process is repeated until a considerable number of servers have their utilization near to the desired level. The hosts whose VMs are migrated are put in sleep mode or powered off. Thus, the number of servers are minimized and at the same time the highest loaded servers do not pass their overload thershold.
Similarly, if some of the servers are overloaded then their VMs will be migrated to servers whose utilization is nearer to the desired level. Thus, in both cases overload probability is minimized, which in fact reduces SLA violations and VM migrations.
Power Efficient heuristics
Minimizing the number of active servers is one but not the only solution to reduce energy consumption in a cloud data center. In a heterogeneous data center, different servers will have different energy consumption. Hence, the heterogeneity of servers in a data centers must also be considered. Power Efficiency(PE) of servers is defined as follows:
PE = CPUtotal/POWERmax ,
where,
CPUtotal is the total processing capacity of host
POWERmax is the power of a host at 100% load
Thus, an efficient VM placement algorithm can:
1) Minimize the number of active servers by using bin-packing heuristics such as FFD and BFD.
2) Favor the host higher PE.
3) Combine the above two rules.
We will discuss algorithms that follow the third rule.
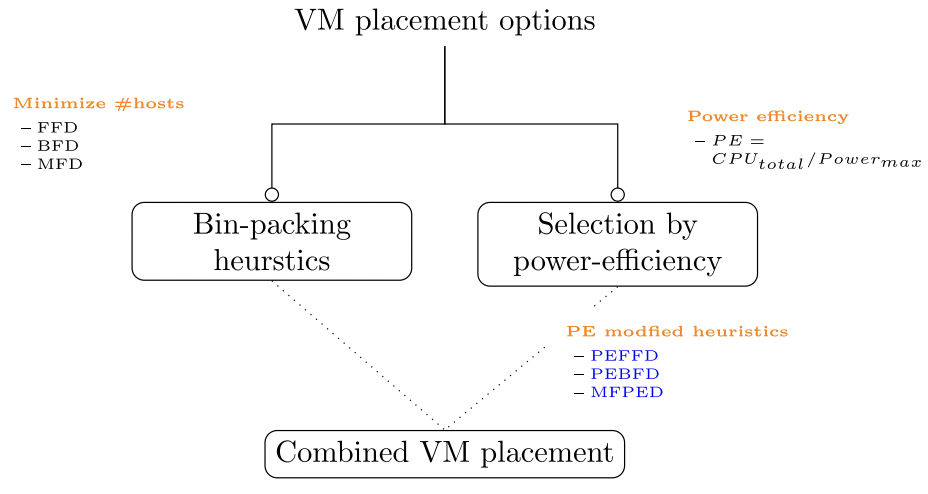 |
| Categorisation of VM placement algorithms [9] |
Power Efficient First Fit Decreasing (PEFFD)
Active hosts are categorized according to their power efficiency and the most efficient ones are favored. If hosts have same power efficiency, then First Fit Decreasing rule is applied. If a suitable host is not found from the active hosts, the same rules are then applied to the inactive hosts.
|

Power Efficient Best Fit Decreasing (PEBFD)
The active hosts are categorized according to their power efficiency, and the most efficient ones are favored. For servers having same power efficiency, Best Fit Decreasing rule is applied to find suitable host. If none of the active hosts are suitable, then the same rule is applied on inactive hosts and the selected host is activated.
|

Medium-Fit Power Efficient Decreasing (MFPED)
The goal here is not only to reduce energy consumption, but also to reduce the effect of overloading. The MFPED will apply Medium-Fit rule on all servers, and in case of a tie the server with better power efficiency will be favored.
|

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comparative analysis of algorithms
Here we will see the comparison of the newly proposed algorithms by Moges and Abebe [7], with two baseline algorithms: MBFD, the VM placement in OpenStack Neat and PABFD which is default VM placement in CloudSim. These algorithms were simulated in CloudSim[3]. The simulations were done three data center scenarios described as follows:
This data center setup was used by Beloglazov[8]. The details are as shown in the image:
The minimum loaded host is chosen for its VMs to be migrated, if other hosts can run its VMs. After migrating all the VMs the previously underloaded host can be turned off.
VM migration
All proposed algorithms have less VM migrations, lower energy consumption and reduced SLA violations.
Default-scenario
 |
| Default scenario [9] |
This data center setup was used by Beloglazov[8]. The details are as shown in the image:
The minimum loaded host is chosen for its VMs to be migrated, if other hosts can run its VMs. After migrating all the VMs the previously underloaded host can be turned off.
Heterogeneous-scenario
Here there are four host types. Two are same as default-scenario, and the other two are quad-core IBM server models: IBM Xeon X3470 (4 X 2933 MIPS) and IBM Xeon X3480 (4 X 3067 MIPS). To make the computational power comparable with default scenario, the number of hosts was kept as 560 (140 of each type).
Homogeneous-scenario
In this scenario, all hosts are of the same type, and have same power efficiency. In default scenario there were two server types, out of which only one, HP ProLiant ML110 G5), is used in the default scenario.
Evaluation metrics
The evaluation metrics were given by Belogazov[8]. Three metrics are used to measure energy efficiency, SLA violation and VM migrations.
Energy efficiency
It is the total data center energy consumption per day.
SLA violation
 |
| Measuring SLA violation [9] |
VM migration
#VM migrations is the number of VM migrations in data center per day.
Results
Performance in default-scenario
 |
| Results under default scenario [9] |
All proposed algorithms have less VM migrations, lower energy consumption and reduced SLA violations.
The improvement of proposed algorithms over baseline MBFD is 8-9% in case of PlanetLab workload traces and 2-3% in case of Bitbrains workload traces. The table below summarizes the performance. MFPED has best performance with respect to all three parameters. Compared with MBFD, MFPED has 32% less OTF and 15% less VM migrations using PlanetLab traces. 64% less OTF and 18% less VM migrations were achieved using Bitbrains traces.
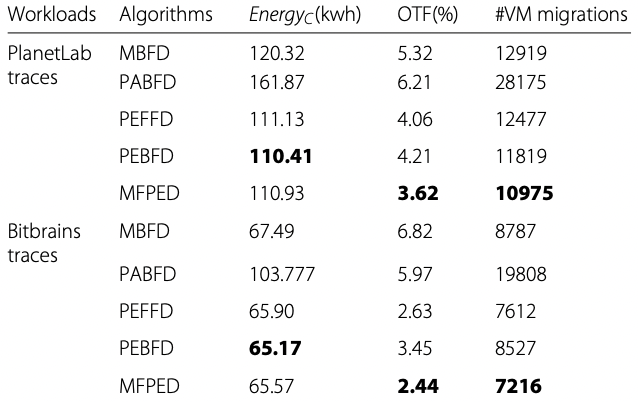 |
| Quantification of performance on default scenario [9] |
Performance in heterogeneous-scenario
 |
| Performance in heterogenous scenario [9] |
Even in heterogeneous scenario all proposed algorithms outperform baseline algorithms. All proposed algorithms give median energy consumption of about 35.3 kwh using PlanetLab workload traces. MBFD has highest energy consumption with a median value of 107.6kwh while that of PABFD is 48.5kwh.
The improvement of proposed algorithms over baseline is about 67%, and 60% in case of Bitbrains traces. The improvement of MFPED over MBFD is 68% for OTF and 46% for VM migrations in PlanetLab traces. For Bitbrains traces MFPED shows 78% less OTF and 40% less VM migrations.
Thus the improvement in this case is even more significant than the improvement in default scenario.
 |
| Quantification of performance in heterogenous scenario [9] |
Performance in homogeneous scenario
 |
| Performance in homogenous scenario [9] |
There is no energy saving by proposed algorithms over baseline algorithms in terms of energy consumption. However, there is improvement in terms of OTF and VM migrations shown by MFPED. Since, all hosts same power efficiency, the only power saving option is to minimize he number of hosts. The worst energy consumption is by PABFD in both traces. MFPED has 19% less OTF and 9% less VM migrations as compared to MBFD in PlanetLab traces, while in Bitbrains traces there is 42% and 14%, lesser OTF and VM migrations respectively.[9]
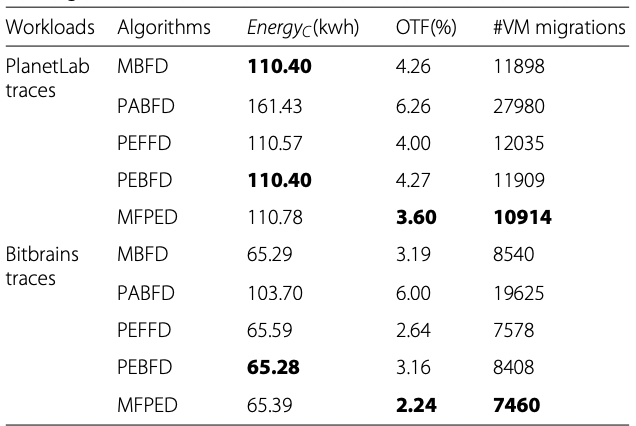 |
| Quantification of performance in homogenous scenario [9] |
Time Complexity of algorithms
For all algorithms the VMs to be migrated are sorted in decreasing order which will take a run time of O(m * log(m)), where m is the number of VM migrations. The algorithms then have a nested loop. The outer loop, loops through the VMs to be migrated, m, and the inner loop, iterates over the number of servers,n. That will take a run time of O(m * n).
Thus, the overall run time is O( m * n + m * log(m)). Usually m > n, the run time complexity can be said to be bounded by O( m * m ).
Conclusion
Several VM placement algorithms have been proposed for VM consolidation. But the existing algorithms used in OpenStack Neat and CloudSim lack support for handling heterogeneity in servers. We studied algorithms which combined bin-packing heuristics and also took the power-efficiency of servers in consideration while making decision regarding VM placement. The newly proposed VM placement algorithms , i.e. MFPED, PEFFD, and PEBFD, outperform the MBFD and PABFD in almost all scenarios. The improvement in energy-efficiency can be
up-to 67% , depending on the workloads, and types of servers in data centers. The MFPED algorithms outperforms all algorithms in reduction in SLA violation and VM migration. The only additional information required for implementing the MFPED algorithm is the peak power consumption of the server, i.e power consumed when CPU utilization is 100% .
up-to 67% , depending on the workloads, and types of servers in data centers. The MFPED algorithms outperforms all algorithms in reduction in SLA violation and VM migration. The only additional information required for implementing the MFPED algorithm is the peak power consumption of the server, i.e power consumed when CPU utilization is 100% .
Future Work
The current traffic status in the data center and network devices also affect the energy consumed for VM migration. There is a scope for VM placement algorithm which considers these factors while deciding the host where the VM is to be placed. VM migration through the region of greater traffic can be avoided.
Thermal aware VM consolidation can be done taking into account server temperature. Cooling systems are also major contributors in the operational cost of data centers. The cost required for cooling the data centers can be reduced by preventing the servers from excessive heating.
References
I have referred the research paper of Moges and Abebe [9] ,
for writing this blog. The work of Anton Beloglazov was of great help,
especially his PhD thesis and this Youtube video of him.
Excellent study report 👍
ReplyDeleteThanks a lot.
ReplyDelete